- download a preliminary PDF
Problem setting: In generic, ecological settings, the visual system faces a tricky problem when searching for one target (from a class of targets) in a cluttered environment. A) It is synthesized in the following experiment: After a fixation period of 200 ms, an observer is presented with a luminous display showing a single target from a known class (here digits) and at a random position. The display is presented for a short period of 500 ms (light shaded area in B), that is enough to perform at most one saccade (here, successful) on the potential target. Finally, the observer has to identify the digit by a keypress. B) Prototypical trace of a saccadic eye movement to the target position. In particular, we show the fixation window and the temporal window during which a saccade is possible (green shaded area). C) Simulated reconstruction of the visual information from the (interoceptive) retinotopic map at the onset of the display and after a saccade, the dashed red box indicating the visual area of the ``what’’ pathway. In contrast to an exteroceptive representation (see A), this demonstrates that the position of the target has to be inferred from a degraded (sampled) image. In particular, the configuration of the display is such that by adding clutter and reducing the size of the digit, it may become necessary to perform a saccade to be able to identify the digit. The computational pathway mediating the action has to infer the location of the target \emph{before seeing it}, that is, before being able to actually identify the target’s category from a central fixation. 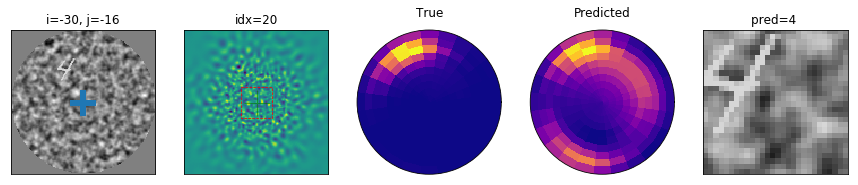
Results: success 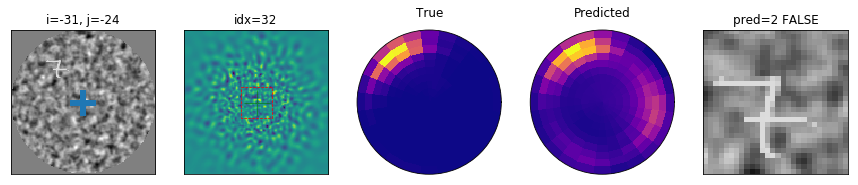
Results: failure to classify 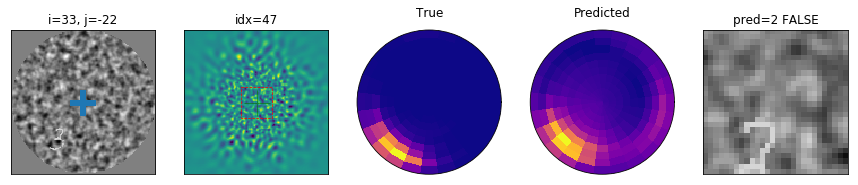
Results: failure to locate
Laurent U Perrinet
Researcher in Computational Neuroscience
My research interests include Machine Learning and computational neuroscience applied to Vision.